Depurando Fluxos de Trabalho¶
Tradução assistida por IA - saiba mais e sugira melhorias
Depurar é uma habilidade crítica que pode te poupar horas de frustração e te ajudar a se tornar um desenvolvedor Nextflow mais eficiente. Ao longo da sua carreira, especialmente no início, você vai encontrar bugs ao construir e manter seus fluxos de trabalho. Aprender abordagens sistemáticas de depuração vai te ajudar a identificar e resolver problemas rapidamente.
Objetivos de aprendizado¶
Nesta side quest, vamos explorar técnicas sistemáticas de depuração para fluxos de trabalho Nextflow:
- Depuração de erros de sintaxe: Usando recursos do IDE e mensagens de erro do Nextflow de forma eficaz
- Depuração de canais: Diagnosticando problemas de fluxo de dados e estrutura de canais
- Depuração de processos: Investigando falhas de execução e problemas de recursos
- Ferramentas de depuração integradas: Aproveitando o modo de prévia do Nextflow, execução com stub e diretórios de trabalho
- Abordagens sistemáticas: Uma metodologia de quatro fases para depuração eficiente
Ao final, você terá uma metodologia robusta de depuração que transforma mensagens de erro frustrantes em roteiros claros para soluções.
Pré-requisitos¶
Antes de embarcar nesta side quest, você deve:
- Ter concluído o tutorial Hello Nextflow ou um curso equivalente para iniciantes.
- Estar confortável com os conceitos e mecanismos básicos do Nextflow (processos, canais, operadores)
Opcional: Recomendamos concluir a side quest IDE Features for Nextflow Development primeiro. Ela oferece uma cobertura abrangente dos recursos do IDE que auxiliam na depuração (realce de sintaxe, detecção de erros, etc.), que usaremos bastante aqui.
0. Primeiros passos¶
Abra o codespace de treinamento¶
Se ainda não tiver feito isso, certifique-se de abrir o ambiente de treinamento conforme descrito em Configuração do Ambiente.
![]()
Acesse o diretório do projeto¶
Vamos acessar o diretório onde estão os arquivos deste tutorial.
Você pode configurar o VSCode para focar neste diretório:
Revise os materiais¶
Você encontrará um conjunto de fluxos de trabalho de exemplo com vários tipos de bugs que usaremos para praticar:
Conteúdo do diretório
.
├── bad_bash_var.nf
├── bad_channel_shape.nf
├── bad_channel_shape_viewed_debug.nf
├── bad_channel_shape_viewed.nf
├── bad_number_inputs.nf
├── badpractice_syntax.nf
├── bad_resources.nf
├── bad_syntax.nf
├── buggy_workflow.nf
├── data
│ ├── sample_001.fastq.gz
│ ├── sample_002.fastq.gz
│ ├── sample_003.fastq.gz
│ ├── sample_004.fastq.gz
│ ├── sample_005.fastq.gz
│ └── sample_data.csv
├── exhausted.nf
├── invalid_process.nf
├── missing_output.nf
├── missing_software.nf
├── missing_software_with_stub.nf
├── nextflow.config
└── no_such_var.nf
Esses arquivos representam cenários comuns de depuração que você encontrará no desenvolvimento do mundo real.
Revise a tarefa¶
Seu desafio é executar cada fluxo de trabalho, identificar o(s) erro(s) e corrigi-los.
Para cada fluxo de trabalho com bugs:
- Execute o fluxo de trabalho e observe o erro
- Analise a mensagem de erro: o que o Nextflow está te dizendo?
- Localize o problema no código usando as pistas fornecidas
- Corrija o bug e verifique se sua solução funciona
- Restaure o arquivo antes de passar para a próxima seção (use
git checkout <filename>)
Os exercícios progridem de erros de sintaxe simples para problemas de execução mais sutis. As soluções são discutidas inline, mas tente resolver cada uma por conta própria antes de ler adiante.
Lista de verificação de prontidão¶
Acha que está pronto para mergulhar de cabeça?
- Entendo o objetivo deste curso e seus pré-requisitos
- Meu codespace está funcionando
- Defini meu diretório de trabalho adequadamente
- Entendo a tarefa
Se você conseguir marcar todas as caixas, pode começar.
1. Erros de Sintaxe¶
Erros de sintaxe são o tipo mais comum de erro que você encontrará ao escrever código Nextflow. Eles ocorrem quando o código não está em conformidade com as regras de sintaxe esperadas do DSL Nextflow. Esses erros impedem que seu fluxo de trabalho seja executado, por isso é importante aprender a identificá-los e corrigi-los rapidamente.
1.1. Chaves ausentes¶
Um dos erros de sintaxe mais comuns, e às vezes um dos mais complexos de depurar, é chaves ausentes ou incompatíveis.
Vamos começar com um exemplo prático.
Execute o pipeline¶
Saída do comando
Elementos-chave das mensagens de erro de sintaxe:
- Arquivo e localização: Mostra qual arquivo e linha/coluna contêm o erro (
bad_syntax.nf:24:1) - Descrição do erro: Explica o que o analisador encontrou que não esperava (
Unexpected input: '<EOF>') - Indicador EOF: A mensagem
<EOF>(End Of File) indica que o analisador chegou ao final do arquivo enquanto ainda esperava mais conteúdo — um sinal clássico de chaves não fechadas
Verifique o código¶
Agora, vamos examinar bad_syntax.nf para entender o que está causando o erro:
Para fins deste exemplo, deixamos um comentário para mostrar onde está o erro. A extensão Nextflow para VSCode também deve estar te dando algumas dicas sobre o que pode estar errado, colocando a chave incompatível em vermelho e destacando o fim prematuro do arquivo:
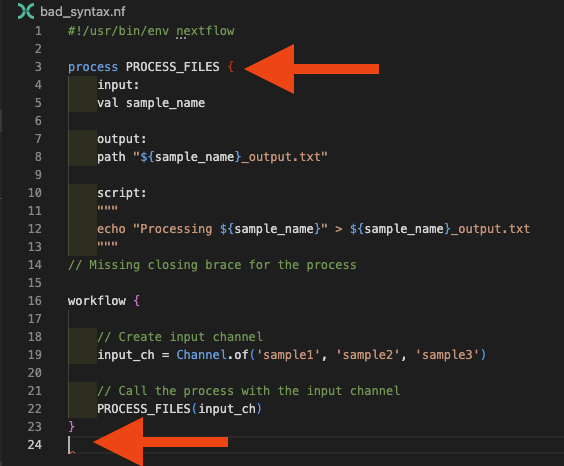
Estratégia de depuração para erros de chaves:
- Use a correspondência de chaves do VS Code (posicione o cursor ao lado de uma chave)
- Verifique o painel de Problemas para mensagens relacionadas a chaves
- Certifique-se de que cada
{de abertura tem um}de fechamento correspondente
Corrija o código¶
Substitua o comentário pela chave de fechamento ausente:
Execute o pipeline¶
Agora execute o fluxo de trabalho novamente para confirmar que funciona:
Saída do comando
1.2. Uso de palavras-chave ou diretivas de processo incorretas¶
Outro erro de sintaxe comum é uma definição de processo inválida. Isso pode acontecer se você esquecer de definir blocos obrigatórios ou usar diretivas incorretas na definição do processo.
Execute o pipeline¶
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `invalid_process.nf` [nasty_jepsen] DSL2 - revision: da9758d614
Error invalid_process.nf:3:1: Invalid process definition -- check for missing or out-of-order section labels
│ 3 | process PROCESS_FILES {
│ | ^^^^^^^^^^^^^^^^^^^^^^^
│ 4 | inputs:
│ 5 | val sample_name
│ 6 |
╰ 7 | output:
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Verifique o código¶
A mensagem de erro indica uma "definição de processo inválida" e mostra o contexto em torno do problema. Olhando para as linhas 3-7, podemos ver inputs: na linha 4, que é o problema. Vamos examinar invalid_process.nf:
Olhando para a linha 4 no contexto do erro, podemos identificar o problema: estamos usando inputs em vez da diretiva correta input. A extensão Nextflow para VSCode também vai sinalizar isso:
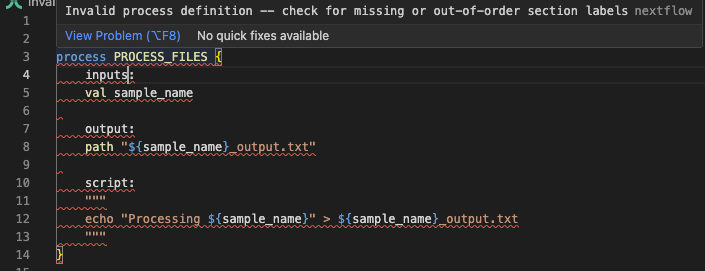
Corrija o código¶
Substitua a palavra-chave incorreta pela correta consultando a documentação:
Execute o pipeline¶
Agora execute o fluxo de trabalho novamente para confirmar que funciona:
Saída do comando
1.3. Uso de nomes de variáveis inválidos¶
Os nomes de variáveis que você usa nos blocos de script devem ser válidos, derivados de entradas ou de código Groovy inserido antes do script. Mas quando você está lidando com complexidade no início do desenvolvimento do pipeline, é fácil cometer erros na nomenclatura de variáveis, e o Nextflow vai te avisar rapidamente.
Execute o pipeline¶
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `no_such_var.nf` [gloomy_meninsky] DSL2 - revision: 0c4d3bc28c
Error no_such_var.nf:17:39: `undefined_var` is not defined
│ 17 | echo "Using undefined variable: ${undefined_var}" >> ${output_pref
╰ | ^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
O erro é detectado em tempo de compilação e aponta diretamente para a variável indefinida na linha 17, com um acento circunflexo indicando exatamente onde está o problema.
Verifique o código¶
Vamos examinar no_such_var.nf:
A mensagem de erro indica que a variável não é reconhecida no template do script, e aí está — você deve conseguir ver ${undefined_var} sendo usada no bloco de script, mas não definida em outro lugar.
Corrija o código¶
Se você receber um erro 'No such variable', pode corrigi-lo definindo a variável (corrigindo nomes de variáveis de entrada ou editando o código Groovy antes do script), ou removendo-a do bloco de script se não for necessária:
Execute o pipeline¶
Agora execute o fluxo de trabalho novamente para confirmar que funciona:
Saída do comando
1.4. Uso incorreto de variáveis Bash¶
Ao começar no Nextflow, pode ser difícil entender a diferença entre variáveis Nextflow (Groovy) e Bash. Isso pode gerar outra forma do erro de variável inválida que aparece ao tentar usar variáveis no conteúdo Bash do bloco de script.
Execute o pipeline¶
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `bad_bash_var.nf` [infallible_mandelbrot] DSL2 - revision: 0853c11080
Error bad_bash_var.nf:13:42: `prefix` is not defined
│ 13 | echo "Processing ${sample_name}" > ${prefix}.txt
╰ | ^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Verifique o código¶
O erro aponta para a linha 13, onde ${prefix} é usado. Vamos examinar bad_bash_var.nf para ver o que está causando o problema:
| bad_bash_var.nf | |
|---|---|
Neste exemplo, estamos definindo a variável prefix em Bash, mas em um processo Nextflow a sintaxe $ que usamos para referenciá-la (${prefix}) é interpretada como uma variável Groovy, não Bash. A variável não existe no contexto Groovy, então recebemos um erro 'no such variable'.
Corrija o código¶
Se você quiser usar uma variável Bash, deve escapar o cifrão assim:
| bad_bash_var.nf | |
|---|---|
Isso instrui o Nextflow a interpretar isso como uma variável Bash.
Execute o pipeline¶
Agora execute o fluxo de trabalho novamente para confirmar que funciona:
Saída do comando
Variáveis Groovy vs Bash
Para manipulações simples de variáveis como concatenação de strings ou operações de prefixo/sufixo, geralmente é mais legível usar variáveis Groovy na seção de script em vez de variáveis Bash no bloco de script:
Essa abordagem evita a necessidade de escapar cifrões e torna o código mais fácil de ler e manter.
1.5. Instruções Fora do Bloco Workflow¶
A extensão Nextflow para VSCode destaca problemas com a estrutura do código que causarão erros. Um exemplo comum é definir canais fora do bloco workflow {} — isso agora é tratado como um erro de sintaxe.
Execute o pipeline¶
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `badpractice_syntax.nf` [intergalactic_colden] DSL2 - revision: 5e4b291bde
Error badpractice_syntax.nf:3:1: Statements cannot be mixed with script declarations -- move statements into a process or workflow
│ 3 | input_ch = channel.of('sample1', 'sample2', 'sample3')
╰ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
A mensagem de erro indica claramente o problema: instruções (como definições de canais) não podem ser misturadas com declarações de script fora de um bloco workflow ou process.
Verifique o código¶
Vamos examinar badpractice_syntax.nf para ver o que está causando o erro:
A extensão VSCode também vai destacar a variável input_ch como sendo definida fora do bloco workflow:
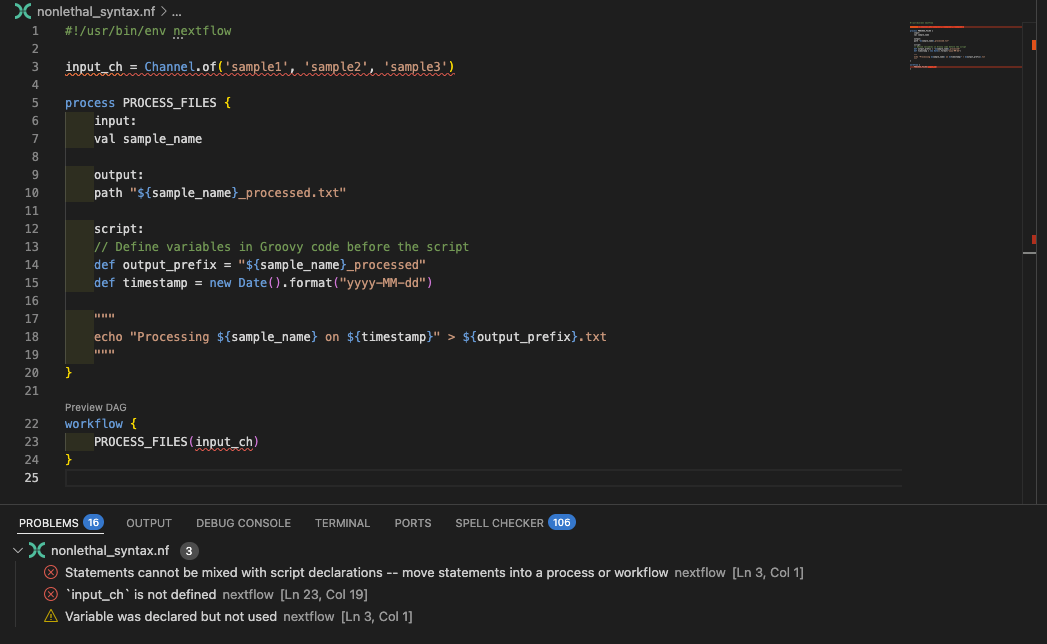
Corrija o código¶
Mova a definição do canal para dentro do bloco workflow:
Execute o pipeline¶
Execute o fluxo de trabalho novamente para confirmar que a correção funciona:
Saída do comando
Mantenha seus canais de entrada definidos dentro do bloco workflow e, em geral, siga quaisquer outras recomendações que a extensão fizer.
Conclusão¶
Você pode identificar e corrigir erros de sintaxe sistematicamente usando mensagens de erro do Nextflow e indicadores visuais do IDE. Erros de sintaxe comuns incluem chaves ausentes, palavras-chave de processo incorretas, variáveis indefinidas e uso inadequado de variáveis Bash vs. Nextflow. A extensão VSCode ajuda a detectar muitos desses erros antes da execução. Com essas habilidades de depuração de sintaxe no seu arsenal, você será capaz de resolver rapidamente os erros de sintaxe Nextflow mais comuns e passar para problemas de execução mais complexos.
O que vem a seguir?¶
Aprenda a depurar erros de estrutura de canal mais complexos que ocorrem mesmo quando a sintaxe está correta.
2. Erros de Estrutura de Canal¶
Erros de estrutura de canal são mais sutis do que erros de sintaxe porque o código é sintaticamente correto, mas as formas dos dados não correspondem ao que os processos esperam. O Nextflow tentará executar o pipeline, mas pode descobrir que o número de entradas não corresponde ao esperado e falhar. Esses erros geralmente aparecem apenas em tempo de execução e exigem uma compreensão dos dados que fluem pelo seu fluxo de trabalho.
Depurando Canais com .view()
Ao longo desta seção, lembre-se de que você pode usar o operador .view() para inspecionar o conteúdo do canal em qualquer ponto do seu fluxo de trabalho. Esta é uma das ferramentas de depuração mais poderosas para entender problemas de estrutura de canal. Exploraremos essa técnica em detalhes na seção 2.4, mas sinta-se à vontade para usá-la enquanto trabalha nos exemplos.
2.1. Número Incorreto de Canais de Entrada¶
Este erro ocorre quando você passa um número diferente de canais do que um processo espera.
Execute o pipeline¶
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `bad_number_inputs.nf` [happy_swartz] DSL2 - revision: d83e58dcd3
Error bad_number_inputs.nf:23:5: Incorrect number of call arguments, expected 1 but received 2
│ 23 | PROCESS_FILES(samples_ch, files_ch)
╰ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Verifique o código¶
A mensagem de erro afirma claramente que a chamada esperava 1 argumento, mas recebeu 2, e aponta para a linha 23. Vamos examinar bad_number_inputs.nf:
Você deve ver a chamada incompatível de PROCESS_FILES, fornecendo múltiplos canais de entrada quando o processo define apenas um. A extensão VSCode também vai sublinhar a chamada do processo em vermelho e fornecer uma mensagem de diagnóstico quando você passar o mouse sobre ela:
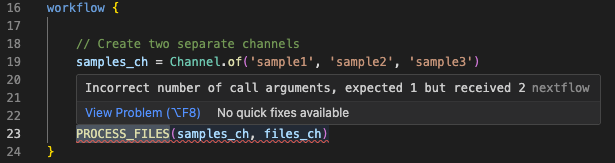
Corrija o código¶
Para este exemplo específico, o processo espera um único canal e não requer o segundo canal, então podemos corrigi-lo passando apenas o canal samples_ch:
Execute o pipeline¶
Saída do comando
Mais comumente do que neste exemplo, você pode adicionar entradas adicionais a um processo e esquecer de atualizar a chamada do workflow adequadamente, o que pode levar a esse tipo de erro. Felizmente, este é um dos erros mais fáceis de entender e corrigir, pois a mensagem de erro é bastante clara sobre a incompatibilidade.
2.2. Esgotamento de Canal (Processo Executa Menos Vezes do que o Esperado)¶
Alguns erros de estrutura de canal são muito mais sutis e não produzem nenhum erro. Provavelmente o mais comum deles reflete um desafio que novos usuários do Nextflow enfrentam ao entender que canais de fila podem ser esgotados e ficar sem itens, fazendo com que o fluxo de trabalho termine prematuramente.
Execute o pipeline¶
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `exhausted.nf` [extravagant_gauss] DSL2 - revision: 08cff7ba2a
executor > local (1)
[bd/f61fff] PROCESS_FILES (1) [100%] 1 of 1 ✔
Este fluxo de trabalho é concluído sem erro, mas processa apenas uma única amostra!
Verifique o código¶
Vamos examinar exhausted.nf para ver se isso está correto:
O processo executa apenas uma vez em vez de três porque o canal reference_ch é um canal de fila que é esgotado após a primeira execução do processo. Quando um canal é esgotado, todo o processo para, mesmo que outros canais ainda tenham itens.
Este é um padrão comum onde você tem um único arquivo de referência que precisa ser reutilizado em múltiplas amostras. A solução é converter o canal de referência em um canal de valor que pode ser reutilizado indefinidamente.
Corrija o código¶
Há algumas maneiras de resolver isso dependendo de quantos arquivos são afetados.
Opção 1: Você tem um único arquivo de referência que está reutilizando bastante. Você pode simplesmente criar um canal de valor, que pode ser usado repetidamente. Há três maneiras de fazer isso:
1a Use channel.value():
| exhausted.nf (fixed - Option 1a) | |
|---|---|
1b Use o operador first() operator:
| exhausted.nf (fixed - Option 1b) | |
|---|---|
1c. Use o operador collect() operator:
| exhausted.nf (fixed - Option 1c) | |
|---|---|
Opção 2: Em cenários mais complexos, talvez onde você tenha múltiplos arquivos de referência para todas as amostras no canal de amostras, você pode usar o operador combine para criar um novo canal que combina os dois canais em tuplas:
| exhausted.nf (fixed - Option 2) | |
|---|---|
O operador .combine() gera um produto cartesiano dos dois canais, então cada item em reference_ch será pareado com cada item em input_ch. Isso permite que o processo seja executado para cada amostra enquanto ainda usa a referência.
Isso requer que a entrada do processo seja ajustada. Em nosso exemplo, o início da definição do processo precisaria ser ajustado da seguinte forma:
| exhausted.nf (fixed - Option 2) | |
|---|---|
Esta abordagem pode não ser adequada em todas as situações.
Execute o pipeline¶
Tente uma das correções acima e execute o fluxo de trabalho novamente:
Saída do comando
Agora você deve ver todas as três amostras sendo processadas em vez de apenas uma.
2.3. Estrutura de Conteúdo de Canal Incorreta¶
Quando os fluxos de trabalho atingem um certo nível de complexidade, pode ser um pouco difícil acompanhar as estruturas internas de cada canal, e as pessoas comumente geram incompatibilidades entre o que o processo espera e o que o canal realmente contém. Isso é mais sutil do que o problema que discutimos anteriormente, onde o número de canais estava incorreto. Neste caso, você pode ter o número correto de canais de entrada, mas a estrutura interna de um ou mais desses canais não corresponde ao que o processo espera.
Execute o pipeline¶
Saída do comando
Launching `bad_channel_shape.nf` [hopeful_pare] DSL2 - revision: ffd66071a1
executor > local (3)
executor > local (3)
[3f/c2dcb3] PROCESS_FILES (3) [ 0%] 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (1)'
Caused by:
Missing output file(s) `[sample1, file1.txt]_output.txt` expected by process `PROCESS_FILES (1)`
Command executed:
echo "Processing [sample1, file1.txt]" > [sample1, file1.txt]_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/d6/1fb69d1d93300bbc9d42f1875b981e
Tip: when you have fixed the problem you can continue the execution adding the option `-resume` to the run command line
-- Check '.nextflow.log' file for details
Verifique o código¶
Os colchetes na mensagem de erro fornecem a pista aqui — o processo está tratando a tupla como um único valor, o que não é o que queremos. Vamos examinar bad_channel_shape.nf:
Você pode ver que estamos gerando um canal composto de tuplas: ['sample1', 'file1.txt'], mas o processo espera um único valor, val sample_name. O comando executado mostra que o processo está tentando criar um arquivo chamado [sample3, file3.txt]_output.txt, que não é a saída pretendida.
Corrija o código¶
Para corrigir isso, se o processo requer ambas as entradas, poderíamos ajustar o processo para aceitar uma tupla:
| bad_channel_shape.nf | |
|---|---|
Execute o pipeline¶
Escolha uma das soluções e execute novamente o fluxo de trabalho:
Saída do comando
2.4. Técnicas de Depuração de Canais¶
Usando .view() para Inspeção de Canais¶
A ferramenta de depuração mais poderosa para canais é o operador .view(). Com .view(), você pode entender a forma dos seus canais em todos os estágios para ajudar na depuração.
Execute o pipeline¶
Execute bad_channel_shape_viewed.nf para ver isso em ação:
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed.nf` [maniac_poisson] DSL2 - revision: b4f24dc9da
executor > local (3)
[c0/db76b3] PROCESS_FILES (3) [100%] 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Verifique o código¶
Vamos examinar bad_channel_shape_viewed.nf para ver como .view() é usado:
Corrija o código¶
Para evitar o uso excessivo de operações .view() no futuro para entender o conteúdo do canal, é aconselhável adicionar alguns comentários para ajudar:
| bad_channel_shape_viewed.nf (with comments) | |
|---|---|
Isso se tornará mais importante à medida que seus fluxos de trabalho crescerem em complexidade e a estrutura do canal se tornar mais opaca.
Execute o pipeline¶
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed.nf` [marvelous_koch] DSL2 - revision: 03e79cdbad
executor > local (3)
[ff/d67cec] PROCESS_FILES (2) | 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Conclusão¶
Muitos erros de estrutura de canal podem ser criados com sintaxe Nextflow válida. Você pode depurar erros de estrutura de canal entendendo o fluxo de dados, usando operadores .view() para inspeção e reconhecendo padrões de mensagens de erro como colchetes indicando estruturas de tupla inesperadas.
O que vem a seguir?¶
Aprenda sobre erros criados por definições de processo.
3. Erros de Estrutura de Processo¶
A maioria dos erros que você encontrar relacionados a processos estará relacionada a erros que você cometeu ao formar o comando, ou a problemas relacionados ao software subjacente. Dito isso, de forma semelhante aos problemas de canal acima, você pode cometer erros na definição do processo que não se qualificam como erros de sintaxe, mas que causarão erros em tempo de execução.
3.1. Arquivos de Saída Ausentes¶
Um erro comum ao escrever processos é fazer algo que gera uma incompatibilidade entre o que o processo espera e o que é gerado.
Execute o pipeline¶
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `missing_output.nf` [zen_stone] DSL2 - revision: 37ff61f926
executor > local (3)
executor > local (3)
[fd/2642e9] process > PROCESS_FILES (2) [ 66%] 2 of 3, failed: 2
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Missing output file(s) `sample3.txt` expected by process `PROCESS_FILES (3)`
Command executed:
echo "Processing sample3" > sample3_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/02/9604d49fb8200a74d737c72a6c98ed
Tip: when you have fixed the problem you can continue the execution adding the option `-resume` to the run command line
-- Check '.nextflow.log' file for details
Verifique o código¶
A mensagem de erro indica que o processo esperava produzir um arquivo de saída chamado sample3.txt, mas o script na verdade cria sample3_output.txt. Vamos examinar a definição do processo em missing_output.nf:
| missing_output.nf | |
|---|---|
Você deve ver que há uma incompatibilidade entre o nome do arquivo de saída no bloco output: e o usado no script. Essa incompatibilidade faz com que o processo falhe. Se você encontrar esse tipo de erro, volte e verifique se as saídas correspondem entre a definição do processo e o bloco de saída.
Se o problema ainda não estiver claro, verifique o próprio diretório de trabalho para identificar os arquivos de saída reais criados:
Para este exemplo, isso nos destacaria que um sufixo _output está sendo incorporado ao nome do arquivo de saída, ao contrário da nossa definição output:.
Corrija o código¶
Corrija a incompatibilidade tornando o nome do arquivo de saída consistente:
Execute o pipeline¶
Saída do comando
3.2. Software ausente¶
Outra classe de erros ocorre devido a erros no provisionamento de software. missing_software.nf é um fluxo de trabalho sintaticamente válido, mas depende de algum software externo para fornecer o comando cowpy que usa.
Execute o pipeline¶
Saída do comando
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Process `PROCESS_FILES (3)` terminated with an error exit status (127)
Command executed:
cowpy sample3 > sample3_output.txt
Command exit status:
127
Command output:
(empty)
Command error:
.command.sh: line 2: cowpy: command not found
Work dir:
/workspaces/training/side-quests/debugging/work/82/42a5bfb60c9c6ee63ebdbc2d51aa6e
Tip: you can try to figure out what's wrong by changing to the process work directory and showing the script file named `.command.sh`
-- Check '.nextflow.log' file for details
O processo não tem acesso ao comando que estamos especificando. Às vezes isso ocorre porque um script está presente no diretório bin do fluxo de trabalho, mas não foi tornado executável. Outras vezes é porque o software não está instalado no contêiner ou ambiente onde o fluxo de trabalho está sendo executado.
Verifique o código¶
Fique atento ao código de saída 127 — ele te diz exatamente o problema. Vamos examinar missing_software.nf:
| missing_software.nf | |
|---|---|
Corrija o código¶
Fomos um pouco desonestos aqui, e na verdade não há nada de errado com o código. Só precisamos especificar a configuração necessária para executar o processo de forma que ele tenha acesso ao comando em questão. Neste caso, o processo tem uma definição de contêiner, então tudo que precisamos fazer é executar o fluxo de trabalho com o Docker habilitado.
Execute o pipeline¶
Configuramos um perfil Docker para você em nextflow.config, então você pode executar o fluxo de trabalho com:
Saída do comando
Nota
Para saber mais sobre como o Nextflow usa contêineres, consulte Hello Nextflow
3.3. Configuração de recursos incorreta¶
Em uso em produção, você estará configurando recursos nos seus processos. Por exemplo, memory define a quantidade máxima de memória disponível para o seu processo, e se o processo exceder isso, seu agendador normalmente encerrará o processo e retornará um código de saída 137. Não podemos demonstrar isso aqui porque estamos usando o executor local, mas podemos mostrar algo semelhante com time.
Execute o pipeline¶
bad_resources.nf tem configuração de processo com um limite de tempo irrealista de 1 milissegundo:
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `bad_resources.nf` [disturbed_elion] DSL2 - revision: 27d2066e86
executor > local (3)
[c0/ded8e1] PROCESS_FILES (3) | 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (2)'
Caused by:
Process exceeded running time limit (1ms)
Command executed:
cowpy sample2 > sample2_output.txt
Command exit status:
-
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/53/f0a4cc56d6b3dc2a6754ff326f1349
Container:
community.wave.seqera.io/library/cowpy:1.1.5--3db457ae1977a273
Tip: you can replicate the issue by changing to the process work dir and entering the command `bash .command.run`
-- Check '.nextflow.log' file for details
Verifique o código¶
Vamos examinar bad_resources.nf:
| bad_resources.nf | |
|---|---|
Sabemos que o processo levará mais de um segundo (adicionamos um sleep para garantir), mas o processo está configurado para expirar após 1 milissegundo. Alguém foi um pouco irrealista com sua configuração!
Corrija o código¶
Aumente o limite de tempo para um valor realista:
| bad_resources.nf | |
|---|---|
Execute o pipeline¶
Saída do comando
Se você se certificar de ler suas mensagens de erro, falhas como essa não devem te confundir por muito tempo. Mas certifique-se de entender os requisitos de recursos dos comandos que você está executando para poder configurar suas diretivas de recursos adequadamente.
3.4. Técnicas de Depuração de Processos¶
Quando os processos falham ou se comportam de forma inesperada, você precisa de técnicas sistemáticas para investigar o que deu errado. O diretório de trabalho contém todas as informações necessárias para depurar a execução do processo.
Usando a Inspeção do Diretório de Trabalho¶
A ferramenta de depuração mais poderosa para processos é examinar o diretório de trabalho. Quando um processo falha, o Nextflow cria um diretório de trabalho para essa execução específica do processo contendo todos os arquivos necessários para entender o que aconteceu.
Execute o pipeline¶
Vamos usar o exemplo missing_output.nf de antes para demonstrar a inspeção do diretório de trabalho (gere novamente uma incompatibilidade de nome de arquivo de saída se necessário):
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `missing_output.nf` [irreverent_payne] DSL2 - revision: 3d5117f7e2
executor > local (3)
[5d/d544a4] PROCESS_FILES (2) | 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (1)'
Caused by:
Missing output file(s) `sample1.txt` expected by process `PROCESS_FILES (1)`
Command executed:
echo "Processing sample1" > sample1_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/1e/2011154d0b0f001cd383d7364b5244
Tip: you can replicate the issue by changing to the process work dir and entering the command `bash .command.run`
-- Check '.nextflow.log' file for details
Verifique o diretório de trabalho¶
Quando você receber esse erro, o diretório de trabalho contém todas as informações de depuração. Encontre o caminho do diretório de trabalho na mensagem de erro e examine seu conteúdo:
# Encontra o diretório de trabalho a partir da mensagem de erro
ls work/02/9604d49fb8200a74d737c72a6c98ed/
Você pode então examinar os arquivos-chave:
Verifique o Script do Comando¶
O arquivo .command.sh mostra exatamente qual comando foi executado:
Isso revela:
- Substituição de variáveis: Se as variáveis Nextflow foram expandidas corretamente
- Caminhos de arquivo: Se os arquivos de entrada foram localizados corretamente
- Estrutura do comando: Se a sintaxe do script está correta
Problemas comuns a procurar:
- Aspas ausentes: Variáveis contendo espaços precisam de aspas adequadas
- Caminhos de arquivo incorretos: Arquivos de entrada que não existem ou estão em locais errados
- Nomes de variáveis incorretos: Erros de digitação em referências de variáveis
- Configuração de ambiente ausente: Comandos que dependem de ambientes específicos
Verifique a Saída de Erro¶
O arquivo .command.err contém as mensagens de erro reais:
Este arquivo mostrará:
- Códigos de saída: 127 (comando não encontrado), 137 (encerrado), etc.
- Erros de permissão: Problemas de acesso a arquivos
- Erros de software: Mensagens de erro específicas da aplicação
- Erros de recursos: Memória/limite de tempo excedido
Verifique a Saída Padrão¶
O arquivo .command.out mostra o que seu comando produziu:
Isso ajuda a verificar:
- Saída esperada: Se o comando produziu os resultados corretos
- Execução parcial: Se o comando começou mas falhou no meio do caminho
- Informações de depuração: Qualquer saída de diagnóstico do seu script
Verifique o Código de Saída¶
O arquivo .exitcode contém o código de saída do processo:
Códigos de saída comuns e seus significados:
- Código de saída 127: Comando não encontrado — verifique a instalação do software
- Código de saída 137: Processo encerrado — verifique os limites de memória/tempo
Verifique a Existência de Arquivos¶
Quando os processos falham devido a arquivos de saída ausentes, verifique quais arquivos foram realmente criados:
Isso ajuda a identificar:
- Incompatibilidades de nome de arquivo: Arquivos de saída com nomes diferentes do esperado
- Problemas de permissão: Arquivos que não puderam ser criados
- Problemas de caminho: Arquivos criados em diretórios errados
Em nosso exemplo anterior, isso nos confirmou que enquanto o sample3.txt esperado não estava presente, sample3_output.txt estava:
Conclusão¶
A depuração de processos requer examinar os diretórios de trabalho para entender o que deu errado. Os arquivos-chave incluem .command.sh (o script executado), .command.err (mensagens de erro) e .command.out (saída padrão). Códigos de saída como 127 (comando não encontrado) e 137 (processo encerrado) fornecem pistas de diagnóstico imediatas sobre o tipo de falha.
O que vem a seguir?¶
Aprenda sobre as ferramentas de depuração integradas do Nextflow e abordagens sistemáticas para solução de problemas.
4. Ferramentas de Depuração Integradas e Técnicas Avançadas¶
O Nextflow fornece várias ferramentas integradas poderosas para depuração e análise da execução do fluxo de trabalho. Essas ferramentas ajudam você a entender o que deu errado, onde deu errado e como corrigi-lo de forma eficiente.
4.1. Saída de Processo em Tempo Real¶
Às vezes você precisa ver o que está acontecendo dentro dos processos em execução. Você pode habilitar a saída de processo em tempo real, que mostra exatamente o que cada tarefa está fazendo enquanto é executada.
Execute o pipeline¶
bad_channel_shape_viewed.nf dos nossos exemplos anteriores imprimiu o conteúdo do canal usando .view(), mas também podemos usar a diretiva debug para ecoar variáveis de dentro do próprio processo, o que demonstramos em bad_channel_shape_viewed_debug.nf. Execute o fluxo de trabalho:
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed_debug.nf` [agitated_crick] DSL2 - revision: ea3676d9ec
executor > local (3)
[c6/2dac51] process > PROCESS_FILES (3) [100%] 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Sample name inside process is sample2
Sample name inside process is sample1
Sample name inside process is sample3
Verifique o código¶
Vamos examinar bad_channel_shape_viewed_debug.nf para ver como a diretiva debug funciona:
| bad_channel_shape_viewed_debug.nf | |
|---|---|
A diretiva debug pode ser uma maneira rápida e conveniente de entender o ambiente de um processo.
4.2. Modo de Prévia¶
Às vezes você quer detectar problemas antes que qualquer processo seja executado. O Nextflow fornece uma flag para esse tipo de depuração proativa: -preview.
Execute o pipeline¶
O modo de prévia permite testar a lógica do fluxo de trabalho sem executar comandos. Isso pode ser bastante útil para verificar rapidamente a estrutura do seu fluxo de trabalho e garantir que os processos estejam conectados corretamente sem executar nenhum comando real.
Nota
Se você corrigiu bad_syntax.nf anteriormente, reintroduza o erro de sintaxe removendo a chave de fechamento após o bloco de script antes de executar este comando.
Execute este comando:
Saída do comando
O modo de prévia é particularmente útil para detectar erros de sintaxe antecipadamente sem executar nenhum processo. Ele valida a estrutura do fluxo de trabalho e as conexões de processo antes da execução.
4.3. Execução com Stub para Teste de Lógica¶
Às vezes os erros são difíceis de depurar porque os comandos demoram muito, requerem software especial ou falham por razões complexas. A execução com stub permite testar a lógica do fluxo de trabalho sem executar os comandos reais.
Execute o pipeline¶
Quando você está desenvolvendo um processo Nextflow, pode usar a diretiva stub para definir comandos 'fictícios' que geram saídas da forma correta sem executar o comando real. Essa abordagem é particularmente valiosa quando você quer verificar se a lógica do seu fluxo de trabalho está correta antes de lidar com as complexidades do software real.
Por exemplo, lembra do nosso missing_software.nf de antes? Aquele onde tínhamos software ausente que impedia a execução do fluxo de trabalho até adicionarmos -profile docker? missing_software_with_stub.nf é um fluxo de trabalho muito semelhante. Se o executarmos da mesma forma, geraremos o mesmo erro:
Saída do comando
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Process `PROCESS_FILES (3)` terminated with an error exit status (127)
Command executed:
cowpy sample3 > sample3_output.txt
Command exit status:
127
Command output:
(empty)
Command error:
.command.sh: line 2: cowpy: command not found
Work dir:
/workspaces/training/side-quests/debugging/work/82/42a5bfb60c9c6ee63ebdbc2d51aa6e
Tip: you can try to figure out what's wrong by changing to the process work directory and showing the script file named `.command.sh`
-- Check '.nextflow.log' file for details
No entanto, este fluxo de trabalho não produzirá erros se o executarmos com -stub-run, mesmo sem o perfil docker:
Saída do comando
Verifique o código¶
Vamos examinar missing_software_with_stub.nf:
| missing_software.nf (with stub) | |
|---|---|
Em relação ao missing_software.nf, este processo tem uma diretiva stub: especificando um comando a ser usado em vez do especificado em script:, no caso de o Nextflow ser executado no modo stub.
O comando touch que estamos usando aqui não depende de nenhum software ou entradas adequadas, e será executado em todas as situações, permitindo-nos depurar a lógica do fluxo de trabalho sem nos preocupar com os internos do processo.
A execução com stub ajuda a depurar:
- Estrutura de canal e fluxo de dados
- Conexões e dependências de processos
- Propagação de parâmetros
- Lógica do fluxo de trabalho sem dependências de software
4.4. Abordagem Sistemática de Depuração¶
Agora que você aprendeu técnicas individuais de depuração — de arquivos de rastreamento e diretórios de trabalho ao modo de prévia, execução com stub e monitoramento de recursos — vamos uni-las em uma metodologia sistemática. Ter uma abordagem estruturada evita que você fique sobrecarregado por erros complexos e garante que você não perca pistas importantes.
Esta metodologia combina todas as ferramentas que cobrimos em um fluxo de trabalho eficiente:
Método de Depuração em Quatro Fases:
Fase 1: Resolução de Erros de Sintaxe (5 minutos)
- Verifique sublinhados vermelhos no VSCode ou no seu IDE
- Execute
nextflow run workflow.nf -previewpara identificar problemas de sintaxe - Corrija todos os erros de sintaxe (chaves ausentes, vírgulas finais, etc.)
- Certifique-se de que o fluxo de trabalho seja analisado com sucesso antes de prosseguir
Fase 2: Avaliação Rápida (5 minutos)
- Leia as mensagens de erro de execução com atenção
- Verifique se é um erro de execução, lógica ou recurso
- Use o modo de prévia para testar a lógica básica do fluxo de trabalho
Fase 3: Investigação Detalhada (15-30 minutos)
- Encontre o diretório de trabalho da tarefa que falhou
- Examine os arquivos de log
- Adicione operadores
.view()para inspecionar canais - Use
-stub-runpara testar a lógica do fluxo de trabalho sem execução
Fase 4: Correção e Validação (15 minutos)
- Faça correções mínimas e direcionadas
- Teste com resume:
nextflow run workflow.nf -resume - Verifique a execução completa do fluxo de trabalho
Usando Resume para Depuração Eficiente
Depois de identificar um problema, você precisa de uma maneira eficiente de testar suas correções sem desperdiçar tempo re-executando partes bem-sucedidas do seu fluxo de trabalho. A funcionalidade -resume do Nextflow é inestimável para depuração.
Você já deve ter encontrado o -resume se trabalhou com o Hello Nextflow, e é importante que você o use bem ao depurar para evitar esperar enquanto os processos antes do seu processo problemático são executados.
Estratégia de depuração com resume:
- Execute o fluxo de trabalho até a falha
- Examine o diretório de trabalho da tarefa que falhou
- Corrija o problema específico
- Retome para testar apenas a correção
- Repita até que o fluxo de trabalho seja concluído
Perfil de Configuração de Depuração¶
Para tornar essa abordagem sistemática ainda mais eficiente, você pode criar uma configuração de depuração dedicada que habilita automaticamente todas as ferramentas que você precisa:
| nextflow.config (debug profile) | |
|---|---|
Então você pode executar o pipeline com este perfil habilitado:
Este perfil habilita saída em tempo real, preserva os diretórios de trabalho e limita a paralelização para facilitar a depuração.
4.5. Exercício Prático de Depuração¶
Agora é hora de colocar a abordagem sistemática de depuração em prática. O fluxo de trabalho buggy_workflow.nf contém vários erros comuns que representam os tipos de problemas que você encontrará no desenvolvimento do mundo real.
Exercício
Use a abordagem sistemática de depuração para identificar e corrigir todos os erros em buggy_workflow.nf. Este fluxo de trabalho tenta processar dados de amostra de um arquivo CSV, mas contém múltiplos bugs intencionais representando cenários comuns de depuração.
Comece executando o fluxo de trabalho para ver o primeiro erro:
Saída do comando
N E X T F L O W ~ version 25.10.2
Launching `buggy_workflow.nf` [wise_ramanujan] DSL2 - revision: d51a8e83fd
ERROR ~ Range [11, 12) out of bounds for length 11
-- Check '.nextflow.log' file for details
Este erro críptico indica um problema de análise em torno das linhas 11-12 no bloco params{}. O analisador v2 detecta problemas estruturais antecipadamente.
Aplique o método de depuração em quatro fases que você aprendeu:
Fase 1: Resolução de Erros de Sintaxe
- Verifique sublinhados vermelhos no VSCode ou no seu IDE
- Execute nextflow run workflow.nf -preview para identificar problemas de sintaxe
- Corrija todos os erros de sintaxe (chaves ausentes, vírgulas finais, etc.)
- Certifique-se de que o fluxo de trabalho seja analisado com sucesso antes de prosseguir
Fase 2: Avaliação Rápida
- Leia as mensagens de erro de execução com atenção
- Identifique se os erros são de execução, lógica ou recursos
- Use o modo -preview para testar a lógica básica do fluxo de trabalho
Fase 3: Investigação Detalhada
- Examine os diretórios de trabalho das tarefas que falharam
- Adicione operadores .view() para inspecionar canais
- Verifique os arquivos de log nos diretórios de trabalho
- Use -stub-run para testar a lógica do fluxo de trabalho sem execução
Fase 4: Correção e Validação
- Faça correções direcionadas
- Use -resume para testar correções de forma eficiente
- Verifique a execução completa do fluxo de trabalho
Ferramentas de Depuração à Sua Disposição:
# Modo de prévia para verificação de sintaxe
nextflow run buggy_workflow.nf -preview
# Perfil de depuração para saída detalhada
nextflow run buggy_workflow.nf -profile debug
# Execução com stub para teste de lógica
nextflow run buggy_workflow.nf -stub-run
# Resume após correções
nextflow run buggy_workflow.nf -resume
Solução
O buggy_workflow.nf contém 9 ou 10 erros distintos (dependendo de como você conta) cobrindo todas as principais categorias de depuração. Aqui está uma análise sistemática de cada erro e como corrigi-lo
Vamos começar com os erros de sintaxe:
Erro 1: Erro de Sintaxe - Vírgula Final
Correção: Remova a vírgula finalErro 2: Erro de Sintaxe - Chave de Fechamento Ausente
Erro 3: Erro de Nome de Variável
Erro 4: Erro de Variável Indefinida
Neste ponto o fluxo de trabalho será executado, mas ainda receberemos erros (por exemplo, Path value cannot be null em processFiles), causados por estrutura de canal incorreta.
Erro 5: Erro de Estrutura de Canal - Saída de Map Incorreta
Mas isso vai quebrar nossa correção para executar heavyProcess() acima, então precisaremos usar um map para passar apenas os IDs de amostra para esse processo:
Erro 6: Estrutura de canal incorreta para heavyProcess
Agora avançamos um pouco mais, mas recebemos um erro sobre No such variable: i, porque não escapamos uma variável Bash.
Erro 7: Erro de Escape de Variável Bash
Agora recebemos Process exceeded running time limit (1ms), então corrigimos o limite de tempo de execução para o processo relevante:
Erro 8: Erro de Configuração de Recursos
Em seguida, temos um erro Missing output file(s) para resolver:
Erro 9: Incompatibilidade de Nome de Arquivo de Saída
Os dois primeiros processos foram executados, mas não o terceiro.
Erro 10: Incompatibilidade de Nome de Arquivo de Saída
Com isso, o fluxo de trabalho completo deve ser executado.
Fluxo de Trabalho Corrigido Completo:
Categorias de Erros Abordadas:
- Erros de sintaxe: Chaves ausentes, vírgulas finais, variáveis indefinidas
- Erros de estrutura de canal: Formas de dados incorretas, canais indefinidos
- Erros de processo: Incompatibilidades de nome de arquivo de saída, escape de variáveis
- Erros de recursos: Limites de tempo irrealistas
Lições-Chave de Depuração:
- Leia as mensagens de erro com atenção — elas frequentemente apontam diretamente para o problema
- Use abordagens sistemáticas — corrija um erro por vez e teste com
-resume - Entenda o fluxo de dados — erros de estrutura de canal são frequentemente os mais sutis
- Verifique os diretórios de trabalho — quando os processos falham, os logs dizem exatamente o que deu errado
Resumo¶
Nesta side quest, você aprendeu um conjunto de técnicas sistemáticas para depurar fluxos de trabalho Nextflow. Aplicar essas técnicas no seu próprio trabalho vai te permitir gastar menos tempo lutando com o computador, resolver problemas mais rapidamente e se proteger de problemas futuros.
Padrões-chave¶
1. Como identificar e corrigir erros de sintaxe:
- Interpretar mensagens de erro do Nextflow e localizar problemas
- Erros de sintaxe comuns: chaves ausentes, palavras-chave incorretas, variáveis indefinidas
- Distinguir entre variáveis Nextflow (Groovy) e Bash
- Usar recursos da extensão VS Code para detecção antecipada de erros
// Chave ausente - procure sublinhados vermelhos no IDE
process FOO {
script:
"""
echo "hello"
"""
// } <-- ausente!
// Palavra-chave incorreta
inputs: // Deve ser 'input:'
// Variável indefinida - escape com barra invertida para variáveis Bash
echo "${undefined_var}" // Variável Nextflow (erro se não definida)
echo "\${bash_var}" // Variável Bash (escapada)
2. Como depurar problemas de estrutura de canal:
- Entender cardinalidade de canal e problemas de esgotamento
- Depurar incompatibilidades de estrutura de conteúdo de canal
- Usar operadores
.view()para inspeção de canal - Reconhecer padrões de erro como colchetes na saída
// Inspeciona o conteúdo do canal
my_channel.view { "Content: $it" }
// Converte canal de fila para canal de valor (evita esgotamento)
reference_ch = channel.value('ref.fa')
// ou
reference_ch = channel.of('ref.fa').first()
3. Como solucionar problemas de execução de processo:
- Diagnosticar erros de arquivo de saída ausente
- Entender códigos de saída (127 para software ausente, 137 para problemas de memória)
- Investigar diretórios de trabalho e arquivos de comando
- Configurar recursos adequadamente
# Verifica o que foi realmente executado
cat work/ab/cdef12/.command.sh
# Verifica a saída de erro
cat work/ab/cdef12/.command.err
# Código de saída 127 = comando não encontrado
# Código de saída 137 = encerrado (limite de memória/tempo)
4. Como usar as ferramentas de depuração integradas do Nextflow:
- Aproveitar o modo de prévia e depuração em tempo real
- Implementar execução com stub para teste de lógica
- Aplicar resume para ciclos de depuração eficientes
- Seguir uma metodologia sistemática de depuração em quatro fases
Referência Rápida de Depuração
Erros de sintaxe? → Verifique os avisos do VSCode, execute nextflow run workflow.nf -preview
Problemas de canal? → Use .view() para inspecionar o conteúdo: my_channel.view()
Falhas de processo? → Verifique os arquivos do diretório de trabalho:
.command.sh- o script executado.command.err- mensagens de erro.exitcode- status de saída (127 = comando não encontrado, 137 = encerrado)
Comportamento misterioso? → Execute com -stub-run para testar a lógica do fluxo de trabalho
Fez correções? → Use -resume para economizar tempo nos testes: nextflow run workflow.nf -resume
Recursos adicionais¶
- Guia de solução de problemas do Nextflow: Documentação oficial de solução de problemas
- Entendendo os canais do Nextflow: Mergulho profundo nos tipos e comportamentos de canal
- Referência de diretivas de processo: Todas as opções de configuração de processo disponíveis
- nf-test: Framework de testes para pipelines Nextflow
- Comunidade Nextflow no Slack: Obtenha ajuda da comunidade
Para fluxos de trabalho em produção, considere:
- Configurar a Seqera Platform para monitoramento e depuração em escala
- Usar contêineres Wave para ambientes de software reproduzíveis
Lembre-se: A depuração eficaz é uma habilidade que melhora com a prática. A metodologia sistemática e o conjunto abrangente de ferramentas que você adquiriu aqui vão te servir bem ao longo de toda a sua jornada de desenvolvimento com Nextflow.
O que vem a seguir?¶
Volte ao menu de Side Quests ou clique no botão no canto inferior direito da página para avançar para o próximo tópico da lista.