Warning
Some of the translations on the training portal are out of date. The translated material may be incomplete or incorrect. We plan to update the translations later this year. In the meantime, please try to work through the English-language material if you can.
12. Cenários de implantação¶
Aplicações genômicas do mundo real podem gerar milhares de tarefas sendo executadas. Nesse cenário, um escalonador de lote (batch scheduler) é comumente usado para implantar um fluxo de trabalho em um cluster de computação, permitindo a execução de muitos trabalhos em paralelo em muitos nós de computação.
O Nextflow possui suporte embutido para os escalonadores de lote mais usados, como o Univa Grid Engine, o SLURM e o IBM LSF. Verifique a documentação do Nextflow para obter a lista completa dos ambientes de computação.
12.1 Implantação em cluster¶
Um recurso importante do Nextflow é a capacidade de desacoplar a implementação do fluxo de trabalho da plataforma de execução de fato. A implementação de uma camada de abstração permite a implantação do fluxo de trabalho resultante em qualquer plataforma de execução suportada pelo framework.
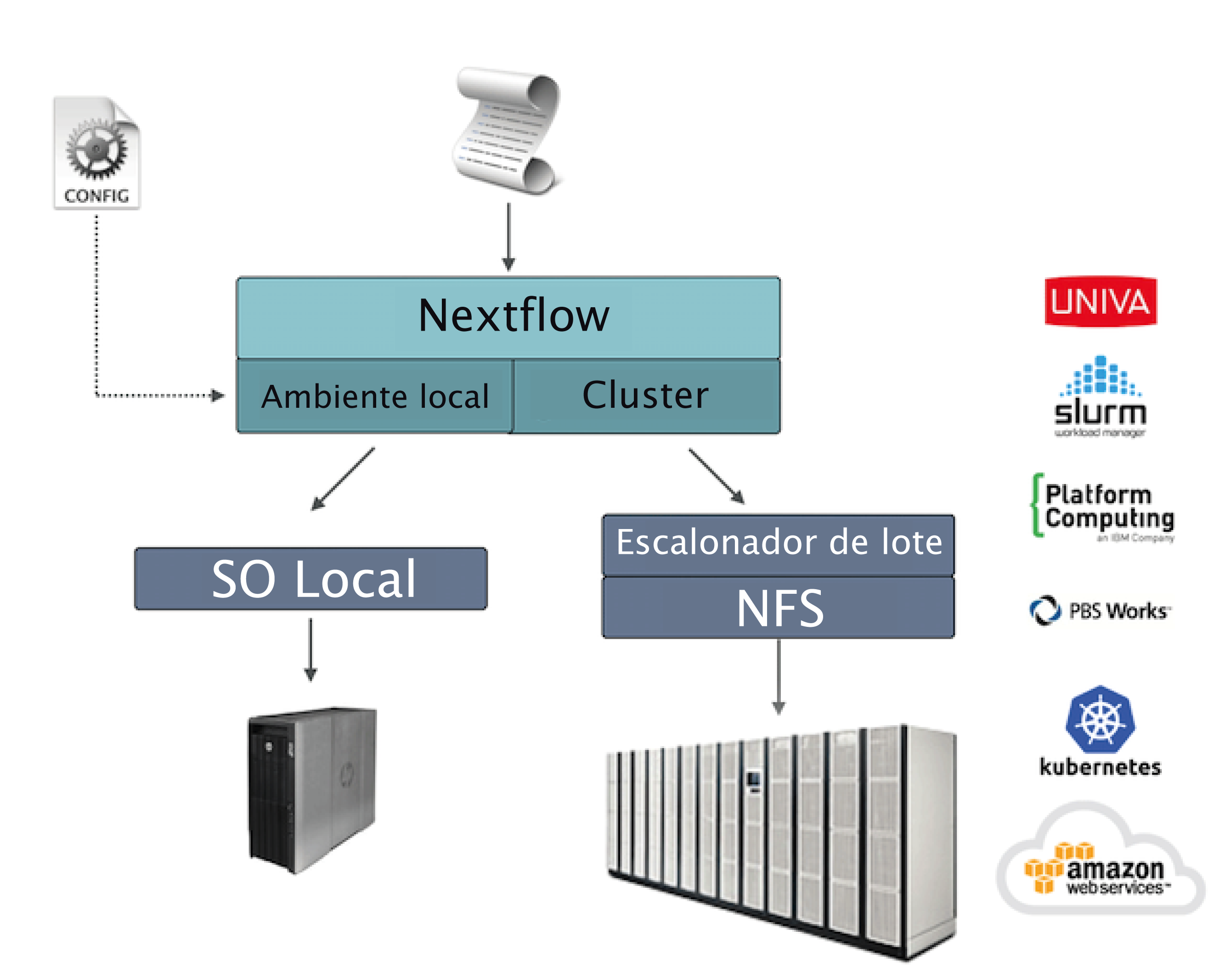
Para executar seu fluxo de trabalho com um escalonador de lote, modifique o arquivo nextflow.config especificando o executor de destino e os recursos de computação necessários, se necessário. Por exemplo:
12.2 Gerenciando recursos do cluster¶
Ao usar um escalonador de lote, geralmente é necessário especificar o número de recursos (ou seja, CPU, memória, tempo de execução etc.) necessários para cada tarefa.
Isso pode ser feito utilizando as seguintes diretivas de processo:
| queue | a fila a ser utilizada no cluster para computação |
| cpus | o número de cpus a serem alocadas para execução da tarefa |
| memory | a quantidade de memória a ser alocada para execução da tarefa |
| time | a quantidade de tempo máxima a ser alocada para execução da tarefa |
| disk | a quantidade de espaço de armazenamento necessária para a execução da tarefa |
12.2.1 Recursos do fluxo de trabalho de modo amplo¶
Use o escopo process para definir os requisitos de recursos para todos os processos em suas aplicações de fluxo de trabalho. Por exemplo:
12.2.2 Submeta o Nextflow como uma tarefa¶
Embora o comando principal do Nextflow possa ser iniciado no nó de login/head de um cluster, esteja ciente de que o nó deve ser configurado para comandos que são executados por um longo período de tempo, mesmo que os recursos computacionais usados sejam insignificantes. Outra opção é enviar o processo principal do Nextflow como uma tarefa no cluster.
Note
Isso requer a configuração do seu cluster para permitir que as tarefas sejam iniciadas a partir dos nós de trabalho, pois o Nextflow enviará novas tarefas e as gerenciará a partir daqui.
Por exemplo, se seu cluster usa Slurm como escalonador de tarefas, você pode criar um arquivo semelhante ao abaixo:
E, em seguida, submeta-o com:
Você pode encontrar mais detalhes sobre o exemplo acima aqui. Você também poderá encontrar mais dicas de como executar o Nextflow em HPC nos seguintes posts de blog:
12.2.3 Configure processos por nome¶
Em aplicações do mundo real, diferentes tarefas precisam de diferentes quantidades de recursos de computação. É possível definir os recursos para uma tarefa específica usando o seletor withName: seguido do nome do processo:
Exercise
Execute o script RNA-Seq (script7.nf) visto na seção de RNAseq, mas especifique dentro do arquivo nextflow.config que o processo de quantificação (QUANTIFICATION) requer 2 CPUs e 5 GB de memória.
12.2.4 Configure processos por rótulos¶
Quando uma aplicação de fluxo de trabalho é composta por muitos processos, pode ser difícil listar todos os nomes de processos e escolher recursos para cada um deles no arquivo de configuração.
Uma melhor estratégia consiste em anotar os processos com uma diretiva de rótulo (label). Em seguida, especifique os recursos no arquivo de configuração usados para todos os processos com o mesmo rótulo.
O script do fluxo de trabalho:
O arquivo de configuração:
12.2.5 Configure vários contêineres¶
Os contêineres podem ser definidos para cada processo em seu fluxo de trabalho. Você pode definir seus contêineres em um arquivo de configuração conforme mostrado abaixo:
Tip
Devo usar um único contêiner pesado ou muitos contêineres leves? Ambas as abordagens têm prós e contras. Um único contêiner é mais simples de construir e manter, porém ao usar muitas ferramentas a imagem pode ficar muito grande e as ferramentas podem criar conflitos umas com as outras. O uso de um contêiner para cada processo pode resultar em muitas imagens diferentes para criar e manter, especialmente quando os processos em seu fluxo de trabalho usam ferramentas diferentes para cada tarefa.
Leia mais sobre seletores de processo de configuração neste link.
12.3 Perfis de configuração¶
Os arquivos de configuração podem conter a definição de um ou mais perfis. Um perfil é um conjunto de atributos de configuração que podem ser ativados/escolhidos ao lançar a execução de um fluxo de trabalho usando a opção de linha de comando -profile.
Os perfis de configuração são definidos usando o escopo especial profiles que agrupa os atributos que pertencem ao mesmo perfil usando um prefixo comum. Por exemplo:
Essa configuração define três perfis diferentes: standard, cluster e nuvem que definem diferentes estratégias de configuração de processo dependendo da plataforma de tempo de execução de destino. Por convenção, o perfil standard é usado implicitamente quando nenhum outro perfil é especificado pelo usuário.
Para ativar um perfil específico, use a opção -profile seguida do nome do perfil:
Tip
Dois ou mais perfis de configuração podem ser especificados separando os nomes dos perfis com uma vírgula:
12.4 Implantação na nuvem¶
AWS Batch é um serviço de computação gerenciada que permite a execução de cargas de trabalho em contêineres na infraestrutura de nuvem da Amazon.
O Nextflow fornece suporte embutido para o AWS Batch, que permite uma implantação simples de um fluxo de trabalho do Nextflow na nuvem, descarregando as execuções de processo como trabalhos em lote.
Uma vez que o ambiente Batch esteja configurado, especifique os tipos de instância a serem usadas e o número máximo de CPUs a serem alocadas. Você precisa criar um arquivo de configuração do Nextflow como o mostrado abaixo:
Clique no ícone no código para ver explicações.
- Defina o AWS Batch como o executor para executar os processos no fluxo de trabalho
- O nome da fila de computação definida no ambiente Batch
- A imagem do contêiner do Docker a ser usada para executar cada trabalho
- O diretório de trabalho do fluxo de trabalho deve ser um bucket AWS S3
- A região da AWS a ser usada
- O caminho da ferramenta de linha de comando da AWS necessária para fazer download/upload de arquivos de/para o contêiner
Tip
A prática recomendada é manter essa configuração como um perfil separado no arquivo de configuração do fluxo de trabalho. Isso permite a execução com um comando simples.
Os detalhes completos sobre a implantação no AWS Batch estão disponíveis nesse link.
12.5 Montagens de volume¶
Elastic Block Storage (EBS) (ou outras formas de armazenamento suportadas) podem ser montados no contêiner da tarefa usando a seguinte configuração:
Vários volumes podem ser especificados usando caminhos separados por vírgulas. A sintaxe usual de montagem de volume do Docker pode ser usada para definir volumes complexos para os quais o caminho do contêiner é diferente do caminho do hospedeiro ou para especificar uma opção somente leitura:
Tip
Esta é uma configuração global que deve ser especificada em um arquivo de configuração do Nextflow e será aplicada a todas as execuções do processo.
Warning
O Nextflow espera que os caminhos estejam disponíveis. Ele não lida com o fornecimento de volumes EBS ou outro tipo de armazenamento.
12.6 Definição de tarefa personalizada¶
O Nextflow cria automaticamente as definições de trabalho do Batch necessárias para executar seus processos de fluxo de trabalho. Portanto, não é necessário defini-las antes de executar seu fluxo de trabalho.
No entanto, você ainda pode precisar especificar uma definição de tarefa personalizada para fornecer controle refinado das definições de configuração de uma tarefa específica (por exemplo, para definir caminhos de montagem personalizados ou outras configurações especiais de uma tarefa no Batch).
Para usar sua própria definição de tarefa em um fluxo de trabalho do Nextflow, use-a no lugar do nome da imagem do contêiner, prefixando-a com a string job-definition://. Por exemplo:
12.7 Imagem personalizada¶
Como o Nextflow exige que a ferramenta de linha de comando da AWS esteja acessível no ambiente de computação, uma solução comum consiste em criar uma Amazon Machine Image (AMI) personalizada e instalá-la de maneira independente (por exemplo, usando o gerenciador de pacotes Conda).
Warning
Ao criar sua AMI personalizada para o AWS Batch, certifique-se de usar a Amazon ECS-Optimized Amazon Linux AMI como imagem base.
O trecho de código a seguir mostra como instalar a ferramenta de linha de comando da AWS com o Miniconda:
Note
A ferramenta aws será colocada em um diretório chamado bin na pasta principal de instalação. As ferramentas não funcionarão corretamente se você modificar essa estrutura de diretórios após a instalação.
Por fim, especifique o caminho completo para a aws no arquivo de configuração do Nextflow, conforme mostrado abaixo:
12.8 Modelo de lançamento¶
Uma abordagem alternativa é criar uma AMI personalizada usando um modelo de lançamento que instala a ferramenta de linha de comando da AWS durante o lançamento da instância por meio de dados de usuário personalizados.
No painel do EC2, crie um modelo de lançamento especificando o campo de dados do usuário:
Em seguida, crie um novo ambiente de computação no painel Batch e especifique o modelo de lançamento recém-criado no campo correspondente.
12.9 Implantação híbrida¶
O Nextflow permite o uso de vários executores na mesma aplicação do fluxo de trabalho. Esse recurso permite a implantação de cargas de trabalho híbridas nas quais algumas tarefas são executados no computador local ou cluster de computação local e algumas tarefas são transferidas para o serviço AWS Batch.
Para ativar esse recurso, use um ou mais seletores de processo em seu arquivo de configuração do Nextflow.
Por exemplo, aplique a configuração do AWS Batch apenas a um subconjunto de processos em seu fluxo de trabalho. Você pode tentar o seguinte:
- Defina o
slurmcomo o executor padrão - Defina a fila para o cluster SLURM
- Configuração de processo(s) com o rótulo
tarefaGrande - Defina
awsbatchcomo o executor para o(s) processo(s) com o rótulotarefaGrande - Defina a fila para o(s) processo(s) com o rótulo
tarefaGrande - Defina a imagem do contêiner para implantar para o(s) processo(s) com o rótulo
tarefaGrande - Defina a região para execução do Batch