13. Scénarios de déploiement¶
Les applications génomiques du monde réel peuvent engendrer l'exécution de milliers de tâches. Dans ce scénario, un planificateur de lots est généralement utilisé pour déployer un workflow dans un cluster informatique, permettant l'exécution de nombreuses tâches en parallèle sur de nombreux nœuds informatiques.
Nextflow a un support intégré pour les plannificateurs batch les plus couramment utilisés, tels que Univa Grid Engine, SLURM et IBM LSF. Consultez la documentation de Nextflow pour obtenir la liste complète des prises en charge plates-formes d'exécution.
13.1 Déploiement du cluster¶
L'une des principales caractéristiques de Nextflow est la capacité de découpler la mise en œuvre du workflow de la plate-forme d'exécution proprement dite. La mise en œuvre d'une couche d'abstraction permet de déployer le workflow résultant sur n'importe quelle plate-forme d'exécution prise en charge par le cadre.
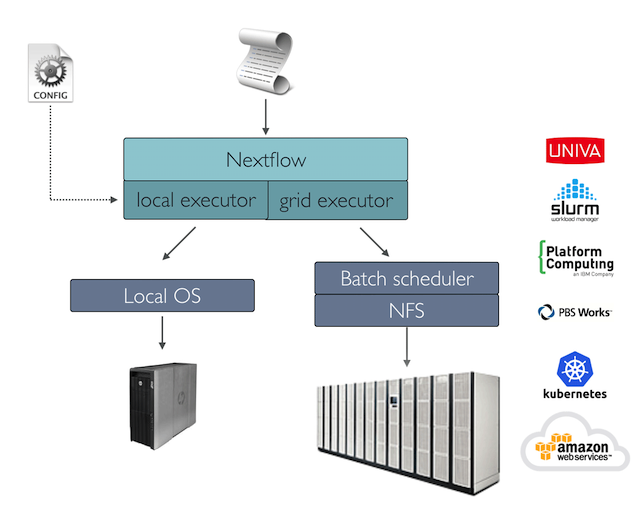
Pour exécuter votre workflow avec un planificateur batch, modifiez le fichier nextflow.config en spécifiant l'exécuteur cible et les ressources informatiques requises si nécessaire. Par exemple, le fichier nextflow.config peut être modifié :
13.2 Gestion des ressources du cluster¶
Lors de l'utilisation d'un planificateur batch, il est souvent nécessaire de spécifier le nombre de ressources (cpus, mémoire, temps d'exécution, etc.) requises par chaque tâche.
Pour ce faire, il convient d'utiliser les directives de processus suivantes :
| queue | la queue de cluster à utiliser pour le calcul |
| cpus | le nombre de cpus à allouer pour l'exécution d'une tâche |
| memoire | la quantité de mémoire à allouer pour l'exécution d'une tâche |
| temps | la quantité maximale de temps à allouer pour l'exécution d'une tâche |
| disque | la quantité de mémoire disk requise pour l'exécution d'une tâche |
13.2.1 Ressources à l'échelle du workflow¶
Utilisez le champ d'application process pour définir les besoins en ressources de tous les processus de vos applications de workflow. Par exemple :
13.2.2 Soumettre Nextflow en tant que tache¶
Bien que la commande principale de Nextflow puisse être lancée sur le nœud de connexion / tête d'un cluster, il faut savoir que le nœud doit être configuré pour des commandes qui s'exécutent pendant une longue période, même si les ressources informatiques utilisées sont négligeables. Une autre option est de soumettre le processus Nextflow principal en tant que tache sur le cluster.
Remarque
Cela nécessite que la configuration de votre cluster permette de lancer des tâches à partir des nœuds de travail, car Nextflow soumettra de nouvelles tâches et les gérera à partir d'ici.
Par exemple, si votre cluster utilise Slurm comme planificateur de tâches, vous pouvez créer un fichier similaire à celui ci-dessous :
Puis soumettez-le avec :
Vous trouverez plus de détails sur l'exemple ci-dessus ici. Vous trouverez d'autres conseils pour l'exécution de Nextflow sur HPC dans les articles de blog suivants :
- 5 astuces Nextflow pour les utilisateurs HPC
- Cinq astuces supplémentaires pour les utilisateurs de Nextflow sur le HPC
13.2.3 Configurer le processus par nom¶
Dans les applications réelles, des tâches différentes nécessitent des ressources informatiques différentes. Il est possible de définir les ressources pour une tâche spécifique en utilisant la commande withName: suivie du nom du processus :
Exercice
Exécuter le script RNA-Seq (script7.nf) de tout à l'heure, mais spécifier que le processus QUANTIFICATION nécessite 2 CPUs et 5 GB de mémoire, dans le fichier nextflow.config.
13.2.4 Configurer le processus par étiquettes¶
Lorsqu'une application de workflow est composée de nombreux processus, il peut être difficile de dresser la liste de tous les noms de processus et de choisir des ressources pour chacun d'entre eux dans le fichier de configuration.
Une meilleure stratégie consiste à annoter les processus avec une directive label. Spécifiez ensuite les ressources dans le fichier de configuration utilisé pour tous les processus ayant le même label.
Le script du workflow :
Le fichier de configuration :
13.2.5 Configurer plusieurs containers¶
Les containers peuvent être définis pour chaque processus de votre flux de travail. Vous pouvez définir leurs conteneurs dans un fichier de configuration, comme indiqué ci-dessous :
Astuce
Dois-je utiliser un seul container fat ou plusieurs containers slim ? Les deux approches ont des avantages et des inconvénients. Un container unique est plus simple à construire et à maintenir, mais lorsque vous utilisez de nombreux outils, l'image peut devenir très volumineuse et les outils peuvent créer des conflits entre eux. L'utilisation d'un container pour chaque processus peut donner lieu à de nombreuses images différentes à construire et à maintenir, en particulier lorsque les processus de votre workflow utilisent des outils différents pour chaque tâche.
Pour en savoir plus sur les sélecteurs de processus de configuration, consultez ce lien.
13.3 Configuration des profils¶
Les fichiers de configuration peuvent contenir la définition d'un ou plusieurs profils. Un profil est un ensemble d'attributs de configuration qui peuvent être activés/choisis lors du lancement de l'exécution d'un workflow en utilisant l'option de ligne de commande -profile.
Les profils de configuration sont définis en utilisant la portée spéciale profiles qui regroupe les attributs appartenant au même profil en utilisant un préfixe commun. Par exemple :
Cette configuration définit trois profils différents : standard, cluster et cloud qui définissent différentes stratégies de configuration de processus en fonction de la plateforme d'exécution cible. Par convention, le profil standard est implicitement utilisé lorsqu'aucun autre profil n'est spécifié par l'utilisateur.
Pour activer un profil spécifique, utilisez l'option -profile suivie du nom du profil :
Astuce
Il est possible de spécifier deux profils de configuration ou plus en séparant les noms des profils par une virgule :
13.4 Déploiement dans le cloud¶
AWS Batch est un service informatique géré qui permet l'exécution de charges de travail containérisées dans l'infrastructure cloud d'Amazon.
Nextflow fournit un support intégré pour AWS Batch qui permet le déploiement transparent d'un workflow Nextflow dans le cloud, en déchargeant les exécutions de processus en tant que tâches Batch.
Une fois que l'environnement Batch est configuré, spécifiez les types d'instances à utiliser et le nombre maximum de CPU à allouer, vous devez créer un fichier de configuration Nextflow comme celui présenté ci-dessous :
Cliquez sur les icônes :material-plus-circle : dans le code pour obtenir des explications.
- Définir AWS Batch comme l'exécuteur pour exécuter les processus dans le workflow
- Le nom de la file d'attente informatique définie dans l'environnement Batch
- L'image du container Docker à utiliser pour exécuter chaque tâche
- Le répertoire de travail du workflow doit être un bucket AWS S3.
- La région AWS à utiliser
- Chemin d'accès à l'outil AWS cli nécessaire pour télécharger des fichiers vers/depuis le container.
Astuce
La meilleure pratique consiste à conserver ce paramètre en tant que profil distinct dans le fichier de configuration de votre flux de travail. Cela permet de l'exécuter à l'aide d'une simple commande.
Les détails complets sur le déploiement par lots d'AWS sont disponibles sur ce lien.
13.5 Montages des volumes¶
Les volumes Elastic Block Storage (EBS) (ou tout autre type de stockage pris en charge) peuvent être montés dans le Container de tâches à l'aide de l'extrait de configuration suivant :
Plusieurs volumes peuvent être spécifiés en utilisant des chemins d'accès séparés par des virgules. La syntaxe habituelle de montage de volume de Docker peut être utilisée pour définir des volumes complexes pour lesquels le chemin du conteneur est différent du chemin de l'hôte ou pour spécifier une option de lecture seule :
Astuce
Il s'agit d'une configuration globale qui doit être spécifiée dans un fichier de configuration Nextflow et qui sera appliquée à toutes les exécutions de processus.
Avertissement
Nextflow s'attend à ce que les chemins d'accès soient disponibles. Il ne gère pas la mise à disposition de volumes EBS ou d'un autre type de stockage.
13.6 Définition des tâches personnalisées¶
Nextflow crée automatiquement les Batch definitions de taches nécessaires à l'exécution de vos processus de workflow. Il n'est donc pas nécessaire de les définir avant d'exécuter votre workflow.
Cependant, vous pouvez toujours avoir besoin de spécifier une définition de travail personnalisée pour permettre un contrôle fin des paramètres de configuration d'un travail spécifique (par exemple, pour définir des chemins de montage personnalisés ou d'autres paramètres spéciaux d'un batch de taches).
Pour utiliser votre propre définition de travail dans un workflow Nextflow, utilisez-la à la place du nom de l'image du conteneur, en la préfixant avec la chaîne job-definition://. Par exemple :
13.7 Image personnalisée¶
Comme Nextflow exige que l'outil AWS CLI soit accessible dans l'environnement informatique, une solution courante consiste à créer une Amazon Machine Image (AMI) personnalisée et à l'installer de manière autonome (par exemple à l'aide du gestionnaire de paquets Conda).
Avertissement
Lorsque vous créez votre AMI personnalisée pour AWS Batch, assurez-vous d'utiliser l'AMI Amazon ECS-Optimized Amazon Linux comme image de base.
L'extrait suivant montre comment installer AWS CLI avec Miniconda :
Remarque
L'outil aws sera placé dans un répertoire nommé bin dans le dossier d'installation principal. Les outils ne fonctionneront pas correctement si vous modifiez la structure de ce répertoire après l'installation.
Enfin, spécifiez le chemin complet aws dans le fichier de configuration de Nextflow comme indiqué ci-dessous :
13.8 Lancer le modèle¶
Une autre approche consiste à créer une AMI personnalisée à l'aide d'un modèle de lancement qui installe l'outil AWS CLI lors du démarrage de l'instance via des données utilisateur personnalisées.
Dans le tableau de bord EC2, créez un modèle de lancement en spécifiant le champ de données de l'utilisateur :
Créez ensuite un nouvel environnement informatique dans le tableau de bord Batch et indiquez le modèle de lancement nouvellement créé dans le champ correspondant.
13.9 Déploiements hybrides¶
Nextflow permet l'utilisation de plusieurs exécuteurs dans la même application de workflow. Cette fonctionnalité permet de déployer des charges de travail hybrides dans lesquelles certains travaux sont exécutés sur l'ordinateur local ou le cluster de calcul local, et d'autres travaux sont déchargés sur le service AWS Batch.
Pour activer cette fonctionnalité, utilisez un ou plusieurs selecteur de processes dans votre fichier de configuration Nextflow.
Par exemple, appliquez la configuration AWS Batch uniquement à un sous-ensemble de processus dans votre flux de travail. Vous pouvez essayer ce qui suit :
- Définir
slurmcomme exécuteur par défaut - Définir la file d'attente pour le cluster SLURM
- Mise en place de processus avec l'étiquette
bigTask - Définir
awsbatchcomme l'exécuteur pour le(s) processus avec le labelbigTask. - Définir la file d'attente pour le(s) processus avec le label
bigTask. - Définir l'image du container à déployer pour le(s) processus avec le label
bigTask. - Définir la région pour l'exécution par batch