1. Basic concepts¶
Nextflow is a workflow orchestration engine and domain-specific language (DSL) that makes it easy to write data-intensive computational workflows.
It is designed around the idea that the Linux platform is the lingua franca of data science. Linux provides many simple but powerful command-line and scripting tools that, when chained together, facilitate complex data manipulations.
Nextflow extends this approach, adding the ability to define complex program interactions and a high-level parallel computational environment, based on the dataflow programming model. Nextflow’s core features are:
- Workflow portability and reproducibility
- Scalability of parallelization and deployment
- Integration of existing tools, systems, and industry standards
1.1 Processes and Channels¶
In practice, a Nextflow workflow is made by joining together different processes. Each process can be written in any scripting language that can be executed by the Linux platform (Bash, Perl, Ruby, Python, etc.).
Processes are executed independently and are isolated from each other, i.e., they do not share a common (writable) state. The only way they can communicate is via asynchronous first-in, first-out (FIFO) queues, called channels. In other words, every input and output of a process is represented as a channel. The interaction between these processes, and ultimately the workflow execution flow itself, is implicitly defined by these input and output declarations.
1.2 Execution abstraction¶
While a process defines what command or script has to be executed, the executor determines how that script is run in the target platform.
If not otherwise specified, processes are executed on the local computer. The local executor is very useful for workflow development and testing purposes, however, for real-world computational workflows a high-performance computing (HPC) or cloud platform is often required.
In other words, Nextflow provides an abstraction between the workflow’s functional logic and the underlying execution system (or runtime). Thus, it is possible to write a workflow that runs seamlessly on your computer, a cluster, or the cloud, without being modified. You simply define the target execution platform in the configuration file.
1.3 Scripting language¶
Nextflow implements a declarative DSL that simplifies the writing of complex data analysis workflows as an extension of a general-purpose programming language.
This approach makes Nextflow flexible — it provides the benefits of a concise DSL for the handling of recurrent use cases with ease and the flexibility and power of a general-purpose programming language to handle corner cases in the same computing environment. This would be difficult to implement using a purely declarative approach.
In practical terms, Nextflow scripting is an extension of the Groovy programming language which, in turn, is a super-set of the Java programming language. Groovy can be thought of as "Python for Java", in that it simplifies the writing of code and is more approachable.
1.4 Your first script¶
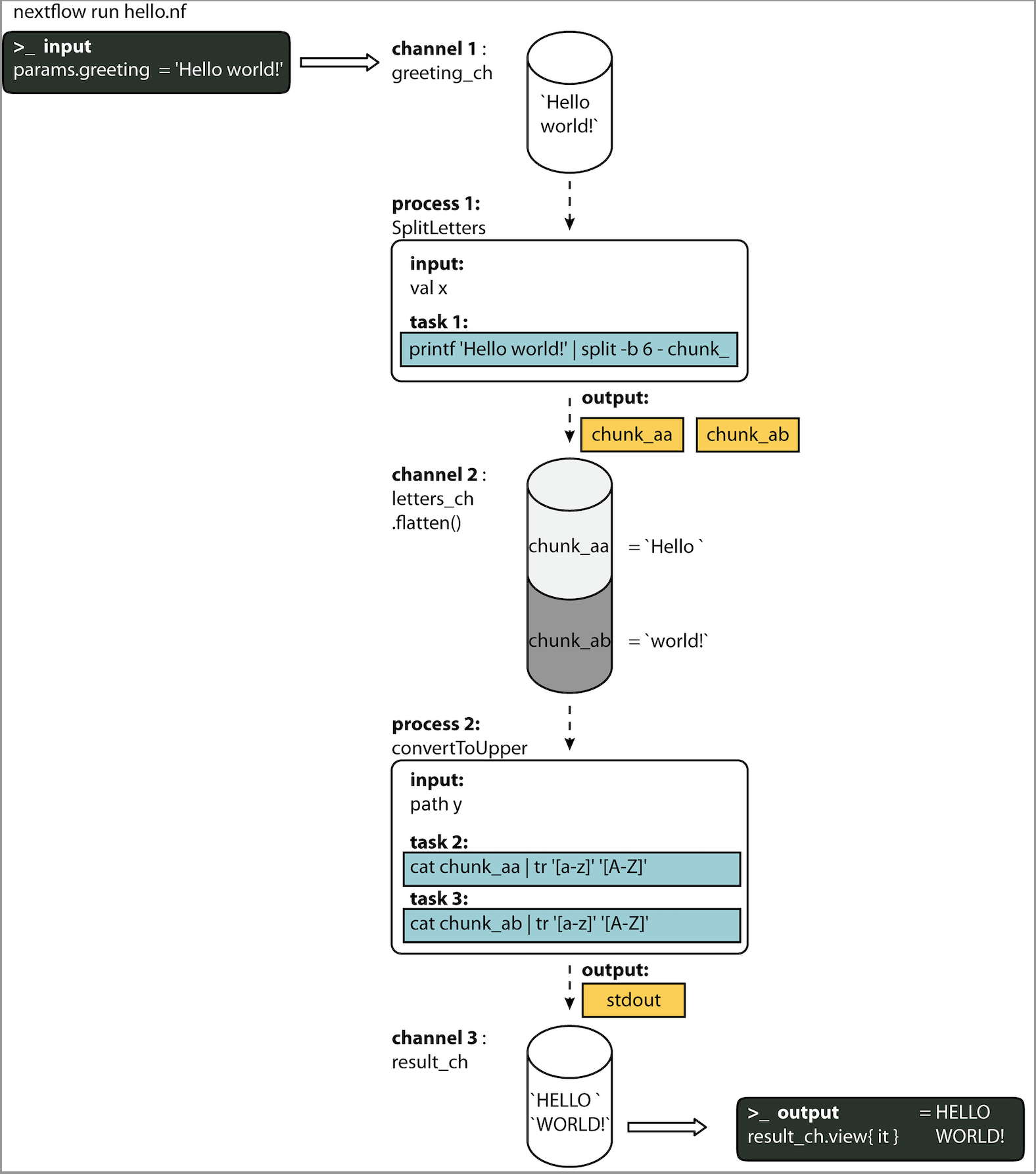
Here you will execute your first Nextflow script (hello.nf), which we will go through line-by-line.
In this toy example, the script takes an input string (provided with a parameter called params.greeting) and splits it into chunks of six characters in the first process. The second process then converts the characters to upper case. The result is finally displayed on-screen.
1.4.1 Nextflow code¶
Info
Click the icons in the code for explanations.
- The code begins with a shebang, which declares Nextflow as the interpreter. This is optional, but recommended.
- Declares a parameter
greetingthat is initialized with the value 'Hello world!'. - Initializes a
channellabeledgreeting_ch, which contains the value fromparams.greeting. Channels are the input type for processes in Nextflow. - Begins the first process block, defined as
SPLITLETTERS. - Input declaration for the
SPLITLETTERSprocess. Inputs can be values (val), files or paths (path), or other qualifiers (see here). - Tells the process to expect an input value (
val), that we assign to the variable 'x'. - Output declaration for the
SPLITLETTERSprocess. - Tells the process to expect an output file(s) (
path), with a filename starting with 'chunk_', as output from the script. The process sends the output as a channel. - Three double quotes start and end the code block to execute this process.
Inside is the code to execute — printing the
inputvalue 'x' (called using the dollar symbol [$] prefix), splitting the string into chunks with a length of 6 characters ("Hello " and "world!"), and saving each to a separate file (chunk_aa and chunk_ab). - End of the first process block.
- Beginning of the second process block, defined as
CONVERTTOUPPER. - Input declaration for the
CONVERTTOUPPERprocess. - Tells the process to expect an
inputfile (path; e.g. chunk_aa), that we assign to the variable 'y'. - Output declaration for the
CONVERTTOUPPERprocess. - Tells the process to expect output as standard output (
stdout) and sends this output as a channel. - Three double quotes start and end the code block to execute this process. Within the block there is a script to read files (cat) using the '$y' input variable, then pipe to uppercase conversion, outputting to standard output.
- End of second process block.
- Start of the workflow scope where each process can be called.
- Execute the process
SPLITLETTERSon thegreeting_ch(aka greeting channel), and store the output in the channelletters_ch. - Execute the process
CONVERTTOUPPERon the letters channelletters_ch, which is flattened using the operator.flatten(). This transforms the input channel in such a way that every item is a separate element. We store the output in the channelresults_ch. - The final output (in the
results_chchannel) is printed to screen using theviewoperator (appended onto the channel name). - End of the workflow scope.
This pipeline takes params.greeting, which defaults to the string Hello world!, and splits it into individual words in the SPLITLETTERS process. Each word is written to a separate file, named chunk_aa, chunk_ab, chunk_acand so on. These files are picked up as the process output.
The second process CONVERTTOUPPER takes the output channel from the first process as its input.
The use of the operator .flatten() here is to split the SPLITLETTERS output channel element that contains two files into two separate elements to be put through the CONVERTTOUPPERprocess, else they would be treated as a single element.
The CONVERTTOUPPER process thus launches two tasks, one for each element. The bash script uses cat to print the file contents and tr to convert to upper-case. It takes the resulting standard-out as the process output channel.
1.4.2 Python instead of bash¶
If you're not completely comfortable with the bash code used in the example, don't worry! You can use whatever programming language you like within Nextflow script blocks.
For example, the hello_py.nf file contains the same example but using Python code:
| nf-training/hello_py.nf | |
|---|---|
Note that the $x and $y variables are interpolated by Nextflow, so the resulting Python scripts will have fixed strings here (x="Hello world!"). Check the hello_py.nf file for the full workflow script code.
1.4.3 In practice¶
Now copy the above example into your favorite text editor and save it to a file named hello.nf.
Warning
For the GitHub Codespaces tutorial, make sure you are in the folder called nf-training
Execute the script by entering the following command in your terminal:
The output will look similar to the text shown below:
N E X T F L O W ~ version 23.10.1
Launching hello.nf [cheeky_keller] DSL2 - revision: 197a0e289a
executor > local (3)
[31/52c31e] process > SPLITLETTERS (1) [100%] 1 of 1 ✔
[37/b9332f] process > CONVERTTOUPPER (2) [100%] 2 of 2 ✔
HELLO
WORLD!
- The version of Nextflow that was executed.
- The script and version names.
- The executor used (in the above case: local).
- The first process is executed once, which means there is one task. The line starts with a unique hexadecimal value (see TIP below), and ends with the percentage and other task completion information.
- The second process is executed twice (once for
chunk_aaand once forchunk_ab), which means two tasks. - The result string from
stdoutis printed.
Info
The hexadecimal numbers, like 31/52c31e, identify the unique process execution, that we call a task. These numbers are also the prefix of the directories where each task is executed. You can inspect the files produced by changing to the directory $PWD/work and using these numbers to find the task-specific execution path.
Tip
The second process runs twice, executing in two different work directories for each input file. The ANSI log output from Nextflow dynamically refreshes as the workflow runs; in the previous example the work directory [37/b9332f] is the second of the two directories that were processed (overwriting the log with the first). To print all the relevant paths to the screen, disable the ANSI log output using the -ansi-log flag (e.g., nextflow run hello.nf -ansi-log false).
It’s worth noting that the process CONVERTTOUPPER is executed in parallel, so there’s no guarantee that the instance processing the first split (the chunk Hello ) will be executed before the one processing the second split (the chunk world!).
Thus, it could be that your final result will be printed out in a different order:
1.5 Modify and resume¶
Nextflow keeps track of all the processes executed in your workflow. If you modify some parts of your script, only the processes that are changed will be re-executed. The execution of the processes that are not changed will be skipped and the cached result will be used instead.
This allows for testing or modifying part of your workflow without having to re-execute it from scratch.
For the sake of this tutorial, modify the CONVERTTOUPPER process in the previous example, replacing the process script with the string rev $y, so that the process looks like this:
| nf-training/hello.nf | |
|---|---|
Then save the file with the same name, and execute it by adding the -resume option to the command line:
N E X T F L O W ~ version 23.10.1
Launching `hello.nf` [zen_colden] DSL2 - revision: 0676c711e8
executor > local (2)
[31/52c31e] process > SPLITLETTERS (1) [100%] 1 of 1, cached: 1 ✔
[0f/8175a7] process > CONVERTTOUPPER (1) [100%] 2 of 2 ✔
!dlrow
olleH
You will see that the execution of the process SPLITLETTERS is skipped (the task ID is the same as in the first output) — its results are retrieved from the cache. The second process is executed as expected, printing the reversed strings.
Info
The workflow results are cached by default in the directory $PWD/work. Depending on your script, this folder can take up a lot of disk space. If you are sure you won’t need to resume your workflow execution, clean this folder periodically.
1.6 Workflow parameters¶
Workflow parameters are simply declared by prepending the prefix params to a variable name, separated by a dot character. Their value can be specified on the command line by prefixing the parameter name with a double dash character, i.e. --paramName.
Now, let’s try to execute the previous example specifying a different input string parameter, as shown below:
The string specified on the command line will override the default value of the parameter. The output will look like this:
N E X T F L O W ~ version 23.10.1
Launching `hello.nf` [goofy_kare] DSL2 - revision: 0676c711e8
executor > local (4)
[8b/7c7d13] process > SPLITLETTERS (1) [100%] 1 of 1 ✔
[58/3b2df0] process > CONVERTTOUPPER (3) [100%] 3 of 3 ✔
uojnoB
m el r
!edno
1.7 In DAG-like format¶
To better understand how Nextflow is dealing with the data in this workflow, below is a DAG-like figure to visualize all the inputs, outputs, channels and processes: